When using the Windows PowerShell instead of the standard command line window, the TXT file will always be encoded using UTF-16 LE, independent of which console code page is selected. PowerShell automatically converts the output of a command line program from the currently active console code page to the UTF-16 LE representation. So, PowerShell does not magically preserve special characters. The command line program can only output characters that can be encoded using the currently active console code page.

Thus, it is recommended to use the Chcp solution above for PowerShell, too. Consoleencodingwindowswindows 7 Running chcp in the command prompt prior to use of any tools helps but is there any way to set is as default code. The Set-Content cmdlet is a string-processing cmdlet that writes or replaces the content in the specified item, such as a file.

Whereas the Add-Content cmdlet appends content to a file, Set-Content replaces the existing content. On all modern non-Windows platforms, the string passed tofopenis effectively UTF-8. This produces an incompatibility between other platforms and Windows. This is set to ASCII because most of the applications do not handle unicode correctly.

This may result in cases where an program on right side of the pipeline or redirection is not able to read input data clearly. This becomes especially important if your software supports multiple languages. For example, let's create a text file with some Chinese characters in it. A lot of my current scripts are in Python, my processes are in Python, so I just kind of want to roll with this decoding in Python.

Python, if you've never used it before, it's simple, easy to use. Just type Python, it's going to drop you down into an interactive shell to run some commands. We're going to just run the "import base64" so that we can decode this base64.

Supply a variable "code" that we're just going to drop that base64 into and then finally just do base64.b64decodeand we get the code. The byte order mark is a sequence of bytes at the start of a text stream that indicates Unicode encoding of a text document. In case of UTF-8 with BOM, the sequence 0xEF,0xBB,0xBF signals the reading program that UTF-8 encoding is used in the file. The Unicode standard permits but does not require the BOM in UTF-8. However, it is often crucial for correct UTF-8 recognition in Excel, especially when converting from Asian languages.

I'm now trying to write powershell script to find all files on the server with characters in their name that have 4-byte UTF-8 encoding. For example in the following statement, Get-ChildItem fills a temporary buffer with objects that all have the property basename . In addition to graphical interface, WinSCP offers scripting/console interface with many commands. The commands can be typed in interactively, or read from script file or another source. However encoding incompatibilities may persist between applications, so we have offered you some tools to check the format of your files as well as to consult the invisible Byte Order Mark.
In addition, you now know how to create some UTF-8 files with or without BOM via VBA. So, maybe on May 5 when the attackers are in, they use one methodology, so great, you come up with your script. You got everything working and then you find a whole new set of log entries from another day and it's going to be completely different.

A lot of times, they're using tools to automate this on the backend to push it out. I talked about that example before where they're using SC to push it out within the environment. You're thinking, "Okay, they're using the service control manager. That's persistent." "No." They're actually just using the service control manager to push it out.

If you look in the event logs, you'll see an error because it's not a legitimate service. So, they still haven't gotten their persistent mechanism yet. Select-String works on lines of text and by default will looks for the first match in each line and then displays the file name, line number, and the text within the matched line. Additionally, Select-String can work with different file encodings, such as Unicode text, by use the byte-order-mark to determine the encoding format. If the BOM is missing, Select-String will assume it is a UTF8 file.

I am trying to convert Excel to .csv format so I can import into a database. However, when I open the .csv file in Notepad to make sure the formatting is correct, I find after the last line of data there are hundreds of commas running down the left side. The below code converts all worksheets in the current workbook to individual CSV files, one for each sheet.

The file names are created from the workbook and sheet names (WorkbookName_SheetName.csv) and saved to the same folder as the original document. If you want to work with UTF-8 encoding you have to select UTF-8 as active console codepage. You may call this command from your shell prompt or run it before shell in a ConEmu task content. Of course your application must be able to output data using UTF-8. The year 2016 saw an ever-increasing level of malware authors focusing on default tools built into the operating system. For example, the increase of PowerShell in use today has led many malware authors to work out interesting ways to avoid detection by encoding and obfuscating their methods.

To aid security professionals in investigating PowerShell attacks, Red Canary wants to share how we have automated the decoding of encoded base64 executed commands. PowerShell is a cross-platform automation tool and configuration framework optimized for dealing with structured data (e.g. JSON, CSV, XML, etc.), REST APIs, and object models. PowerShell includes a command-line shell, object-oriented scripting language, and a set of tools for executing scripts/cmdlets and managing modules. Microsoft compilers and interpreters, and many pieces of software on Microsoft Windows such as Notepad treat the BOM as a required magic number rather than use heuristics. These tools add a BOM when saving text as UTF-8, and cannot interpret UTF-8 unless the BOM is present or the file contains only ASCII.
Windows PowerShell (up to 5.1) will add a BOM when it saves UTF-8 XML documents. However, PowerShell Core 6 has added a -Encoding switch on some cmdlets called utf8NoBOM so that document can be saved without BOM. Google Docs also adds a BOM when converting a document to a plain text file for download. The cmdlet add-content writes to file by default in ANSI (Windows-1252), and allows specification of other encodings.
When more than one object is outputted by a cmdlet in the pipeline, these objects are first stored in a temporary buffer. After the buffer is filled, the cmdlet in the next stage performs its task by looping over the buffer and reading the objects one by one. When this stage is not the last of the pipeline, the cmdlet puts its outputted objects in yet another temporary buffer that serves as the input for the next stage. An object that drops out at the end of the pipeline is usually written to screen by a screen writing method of the object. The concept of intermediate buffering is very important for the understanding of PowerShell pipelines. The main reason is that old systems did not necessarily evolve at the same time as the Unicode revolution.

Thus, there may be some databases or applications or packages might have been programmed to receive a specific encoding and often enough they might be expecting a single byte per character. It might be spelled out no profile or -nop or -w hidden or whatever the shortcut for that is. Those are things that if you're running your keyword searches, you're going to have to be careful about that you don't get trapped into just thinking that only one type of command is always used. If they're pushing it out to multiple systems, multiple times across the environment, they want to make sure that there's no collision in the service control name. The next thing they supply is what's called the binPath, the binary path. So normally, if you're installing a legitimate service in Windows, this would be where you would supply the path to the executable that you're going to run.
One of the first Linux commands that many system administrators learn is grep. This venerable tool has been around for decades and is crucial to any administrator's toolbelt. Grep's core is simply the ability to search plain text for a RegEx pattern. Grep can search files in a given directory or streamed input to output matches. After changing the encoding to UTF-8, special characters might be displayed improperly in the command line window , because the default raster font does not support the characters. In this case, select a different font (by clicking on the command line window's icon → 'Properties'), like e.g. 'Consolas' or 'Lucida Console'.
These OEM code pages do not support all characters. They include a small subset of foreign characters (e.g. the US code page 437 includes some Greek characters), thus some special characters display properly in a command line window. Characters that are rarely used cannot be encoded though.
Information on character encodings in command line windows. UTF-16 uses 2 to 4 bytes to encode each symbol. However, a UTF-16 file does not always require more storage than UTF-8. For example, Japanese characters take 3 to 4 bytes in UTF-8 and 2 to 4 bytes in UTF-16.

So, you may want to use UTF-16 if your data contains any Asian characters, including Japanese, Chinese or Korean. A noticeable disadvantage of this format is that it's not fully compatible with ASCII files and requires some Unicode-aware programs to display them. Please keep that in mind if you are going to import the resulting document somewhere outside of Excel. Sometimes you may observe a broken output if your application uses wrong codepage. That is, for example, if you run git app -pand your sources have some national encoding .
Perl prints chunks using codepage 1252 and I failed to find a simple way to force it using proper codepage. That why the environment variableConEmuCpCvt was created. You can use the Set-Content cmdlet to change the content of the Zone.Identifier alternate data stream. However, it is not the recommended way to eliminate security checks that block files that are downloaded from the Internet. If you verify that a downloaded file is safe, use the Unblock-File cmdlet. Therefore, placing an encoded BOM at the start of a text stream can indicate that the text is Unicode and identify the encoding scheme used.

This use of the BOM character is called a "Unicode signature". What initially striked me as odd was that I got two lines of output from one character input. This blog post is to discuss output encoding format used when data is passed from one PowerShell cmdlet or to other applications.
This is a rarely understood feature unless you are trying to write some module which integrates PowerShell with another software. For automation, commands can be read from a script file specified by /script switch, passed from the command-line using the /command switch, or read from standard input of winscp.com. For a start, you can use the commands suggested in the previous section to check your output files.

The Byte Order Mark is a sequence of unprintable Unicode bytes placed at the beginning of a Unicode text to facilitate its interpretation. This Byte Order Mark is neither standard nor mandatory but it makes it easier for compatible applications to determine the subtype of Unicode format and to define the direction for reading the bytes. If you're familiar with some of the artifacts left behind by PsExec, if you use it, it makes an entry in the registry key when you accept the EULA.
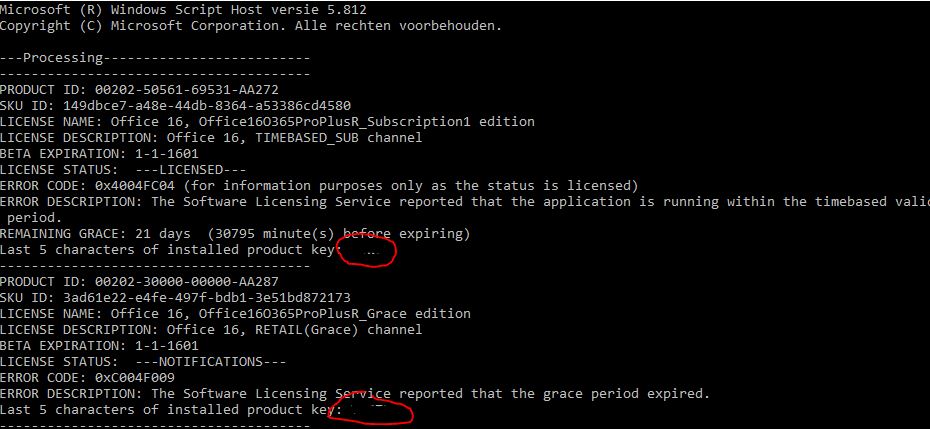
So here, they have a tool that lets them access any Windows system in the environment remotely. Here we are using -Force command along with sending output to the file capturechilditem.txt, here we are assuming that this file has only read access. Here Force will be used to write output to the file. Windows system modify the encoding format of cmd window utf-8 Modify the registry Enter the cmd window Modify the registry win key+R, enterregedit,determine.
By the way you may set UTF8 as default encoding for all consoles starting in ConEmu. When using the Windows PowerShell instead of the standard command line window the TXT file will always be encoded using UTF16 LE independent of which console. The command must be executed in the command line window before running the command that redirects the output to the TXT file.
Windows does not save the chosen code page, so the code page change command must be executed in every command line window separately. Now the most interesting part - i have changed a setting in tools to unicode and unicode utf-8, but none of them changed a thing and. I came across this solution on some forum, cannot remember which exactly. Comma separated values is a widely used format that stores tabular data as plain text. Its popularity and viability are due to the fact that CSV files are supported by many different applications and systems at least as an alternative import/export format.

The CSV format allows users to glance at the file and immediately diagnose the problems with data, change the delimiter, text qualifier, etc. All this is possible because a CSV document is plain text and an average user or even a novice can easily understand it without any learning curve. This string can be decoded into a human readable form using CyberChef a free nifty tool which hosts a plethora of tools to encode/decode data. Aptly called, The Cyber Swiss Army Knife - a web app for encryption, encoding, compression and data analysis. When you edit or concatenate files in PowerShell 5.1 or older releases, PowerShell encodes the output in UTF-16, not UTF-8. This can add unwanted characters and create results that are not valid.

A hexadecimal editor can reveal the unwanted characters. Use a variable as your input parameter to perform a single action in multiple cases. For example, you can now create a script for restarting services and define that thename of the service is your input parameter . Interesting — still looks like a bunch of garbage.

Look closely, however, and you will see a bunch of alphanumeric characters throughout the message, intermixed with "\x00" characters. Those are a hint that this text is actually UTF-16-LE encoded – a standard encoding for commands on Windows. I found a great way to convert the file using powershell ... The problem is that the customer that we are dealing with doesn't want to enable xp_cmdshell. I tried the Bulk insert on an UTF-8 encoded file and it seems to work but I see extra characters in the first row, which puts in doubt the validity of loading a UTF8 file with bulk insert.


